2 Analiza jednej zmiennej
Statystyka opisowa (opis statystyczny) to zbiór metod statystycznych służących do – surprise, surprise – opisu (w sensie przedstawienia sumarycznego) zbioru danych. W zależności od typu danych (przekrojowe, czasowe, przestrzenne) oraz sposobu pomiaru (dane nominalne, porządkowe liczbowe) należy używać różnych metod.
W przypadku danych przekrojowych opis statystyczny nazywany jest analizą struktury i sprowadza się do opisania danych z wykorzystaniem:
tablic (statystycznych);
wykresów;
parametrów (takich jak średnia czy mediana).
Rozkład zmiennej (cechy) to przyporządkowanie wartościom zmiennej odpowiedniej liczby wystąpień w postaci liczebności albo częstości (popularnych procentów).
Analiza struktury (dla jednej zmiennej) obejmuje:
określenie tendencji centralnej (miary położenia: wartość przeciętna, mediana, dominanta);
zróżnicowanie wartości (rozproszenie: odchylenie standardowe, rozstęp ćwiartkowy);
asymetrię (rozłożenie wartości zmiennej wokół średniej).
2.1 Tablice statystyczne
Tablica statystyczna to (w podstawowej formie) dwukolumnowa tabela zawierająca wartości zmiennej oraz odpowiadające tym wartościom liczebności (i/lub częstości).
Tablica dla zmiennej niemierzalnej (nominalnej albo porządkowej).
2.1 Absolwenci studiów pielęgniarskich w wybranych krajach UE
Tablica: Absolwenci studiów pielęgniarskich w wybranych krajach UE w roku 2018
| kraj | liczba absolwentów |
|---|---|
| Belgium | 7203 |
| Germany | 35742 |
| Spain | 9936 |
| France | 25757 |
| Italy | 11207 |
| Netherlands | 9920 |
| Poland | 9070 |
| Romania | 18664 |
Źródło: Eurostat, tablica Health graduates (HLTH_RS_GRD)
W przykładzie jednostką statystyczną jest absolwent studiów pielęgniarskich w roku 2018, badaną zmienną zaś kraj, w którym ukończył studia.
Tablica dla zmiennej mierzalnej liczbowej skokowej.
Przypomnijmy, że zmienna skokowa to taka zmienna, która może przyjąć skończoną (przeliczalną) liczbę wartości.
Jeżeli tych wartości jest mało, to tablica zawiera wyliczenie wartości zmiennej i odpowiadających im liczebności. Jeżeli liczba wariantów zmiennej jest duża, to tablica zawiera klasy wartości (przedziały wartości) oraz odpowiadające im liczebności.
Liczba przedziałów jest dobierana metodą prób i błędów, tak aby:
przedziały wartości były jednakowej rozpiętości;
na zasadzie wyjątku dopuszcza się, aby pierwszy i ostatni przedział były otwarte, tj. nie miały dolnej (pierwszy) lub górnej (ostatni) granicy;
nie było przedziałów z zerową liczebnością;
przedziałów nie było za dużo ani za mało (typowo 5–15);
większość populacji nie znajdowała się w jednym albo dwóch przedziałach.
2.2 Gospodarstwa domowe według liczby osób
Tablica: Gospodarstwa domowe w mieście Kwidzyn według liczby osób w roku 2021
| liczba osób | liczba gospodarstw | % |
|---|---|---|
| 1 | 2790 | 21,65 |
| 2 | 3420 | 26,54 |
| 3 | 2618 | 20,32 |
| 4 | 2246 | 17,43 |
| 5 i więcej | 1813 | 14,07 |
| razem | 12887 | 100,00 |
Źródło: Bank danych lokalnych GUS, podgrupa P4287/Gospodarstwa domowe według liczby osób
W powyższym przykładzie druga kolumna tablicy zawiera liczebności a trzecia częstości (udziały procentowe). W 1813 gospodarstwach domowych mieszkało 5 i więcej osób, co stanowiło 14,1% wszystkich gospodarstw domowych w Kwidzynie.
Tablica dla zmiennej mierzalnej liczbowej ciągłej
Przypomnijmy, że zmienna ciągła to taka zmienna, która może przyjąć nieskończoną i nieprzeliczalną liczbę wartości.
Tablica zawiera klasy (przedziały) wartości oraz odpowiadające im liczebności.
Liczba przedziałów jest dobierana metodą prób i błędów, tak aby:
przedziały wartości były jednakowej rozpiętości;
na zasadzie wyjątku dopuszcza się, aby pierwszy i ostatni przedział były otwarte, tj. nie miały dolnej (pierwszy) lub górnej (ostatni) granicy;
nie było przedziałów z zerową liczebnością;
przedziałów nie było za dużo ani za mało (typowo 8–15);
większość populacji nie znajdowała się w jednej czy dwóch przedziałach;
zwykle przyjmuje się za końce przedziałów okrągłe liczby, bo dziwnie by wyglądało, gdyby koniec przedziału był równy np. 1,015 zamiast 1,0.
2.3 Dzietność kobiet na świecie
Współczynnik dzietności (fertility ratio albo FR) – przeciętna liczba urodzonych dzieci przypadająca na jedną kobietę w wieku rozrodczym (15–49 lat). Przyjmuje się, iż FR między 2,10–2,15 zapewnia zastępowalność pokoleń.
Dane dotyczące dzietności dla wszystkich krajów świata pobrano ze strony https://ourworldindata.org/grapher/fertility-rate-complete-gapminder).
Zbudujmy tablicę przedstawiającą rozkład współczynników dzietności w roku 2018. Wszystkich krajów jest 201. Wartość minimalna współczynnika wynosi 1,22, a wartość maksymalna to 7,13. Decydujemy się na rozpiętość przedziału równą 0,5; dolny koniec pierwszego przedziału przyjmujemy jako 1,0.
Tablica: Kraje świata według współczynnika dzietności (2018)
| Wsp. dzietności | liczba krajów |
|---|---|
| 1,0–1,5] | 24 |
| 1,5–2,0] | 61 |
| 2,0–2,5] | 40 |
| 2,5–3,0] | 17 |
| 3,0–3,5] | 8 |
| 3,5–4,0] | 15 |
| 4,0–4,5] | 11 |
| 4,5–5,0] | 12 |
| 5,0–5,5] | 6 |
| 5,5–6,0] | 5 |
| 6,0 i więcej | 2 |
Źródło: https://ourworldindata.org/grapher/fertility-rate-complete-gapminder
Zapis 1,0–1,5] oznacza przedział od 1,0 do 1,5, przy czym dolny koniec nie należy
do przedziału, a górny tak. Który koniec „wchodzi“, a który nie powinien być
jasno oznaczony. Zwykle jest tak jak w przykładzie: górny „wchodzi“, dolny „nie wchodzi“.
Każda tablica statystyczna musi mieć:
Część liczbową (kolumny i wiersze);
- żadna rubryka w części liczbowej nie może być pusta (żelazna zasada); w szczególności brak danych należy zaznaczyć umownym symbolem.
Część opisową:
- tytuł tablicy;
- nazwy (opisy zawartości) wierszy;
- nazwy (opisy zawartości) kolumn;
- wskazanie źródła danych;
- ewentualne uwagi odnoszące się do danych liczb.
Pominięcie czegokolwiek z powyższego jest ciężkim błędem. Jeżeli nie ma danych (a często – z różnych powodów – tak właśnie jest, należy to zaznaczyć, a nie pozostawiać pustą rubrykę).
2.2 Wykresy
Wykresy statystyczne są graficzną formą prezentacji materiału statystycznego. Są mniej precyzyjne i szczegółowe niż tablice, natomiast bardziej sugestywne.
Celem jest pokazanie rozkładu wartości zmiennej w populacji: jakie wartości występują często, a jakie rzadko, jak bardzo wartości różnią się między sobą. Jak różnią się rozkłady dla różnych, ale logicznie powiązanych populacji (np. rozkład czegoś w kraju A i B albo w roku X, Y i Z).
Dla realizacji tego celu stosuje się:
wykres słupkowy (skala nominalna/porządkowa);
wykres kołowy (skala nominalna/porządkowa);
histogram (albo wykres słupkowy dla skal nominalnych).
Uwaga: wykres kołowy jest zdecydowanie gorszy od wykresu słupkowego i nie jest zalecany. Każdy wykres kołowy można wykreślić jako słupkowy i w takiej postaci będzie on bardziej zrozumiały i łatwiejszy w interpretacji.
Podobnie jak tablice, rysunki powinny być opatrzone tytułem oraz zawierać źródło wskazujące na pochodzenie danych (zobacz przedstawione przykłady).
2.2.1 Skala nominalna i porządkowa
Wykres słupkowy (bar chart)
Na wykresie słupkowym długość każdego prostokąta (słupka) jest proporcjonalna do liczebności, którą reprezentuje. Wartości zmiennej (etykiety) są umieszczane pod lub obok słupka. Słupki można rysować pionowo lub poziomo (jak na poniższym przykładzie). Jeżeli etykiety są długie, to należy słupki rysować poziomo, bo wtedy można zmieścić etykiety bez potrzeby ich obracania o 90° czy skracania.
2.4 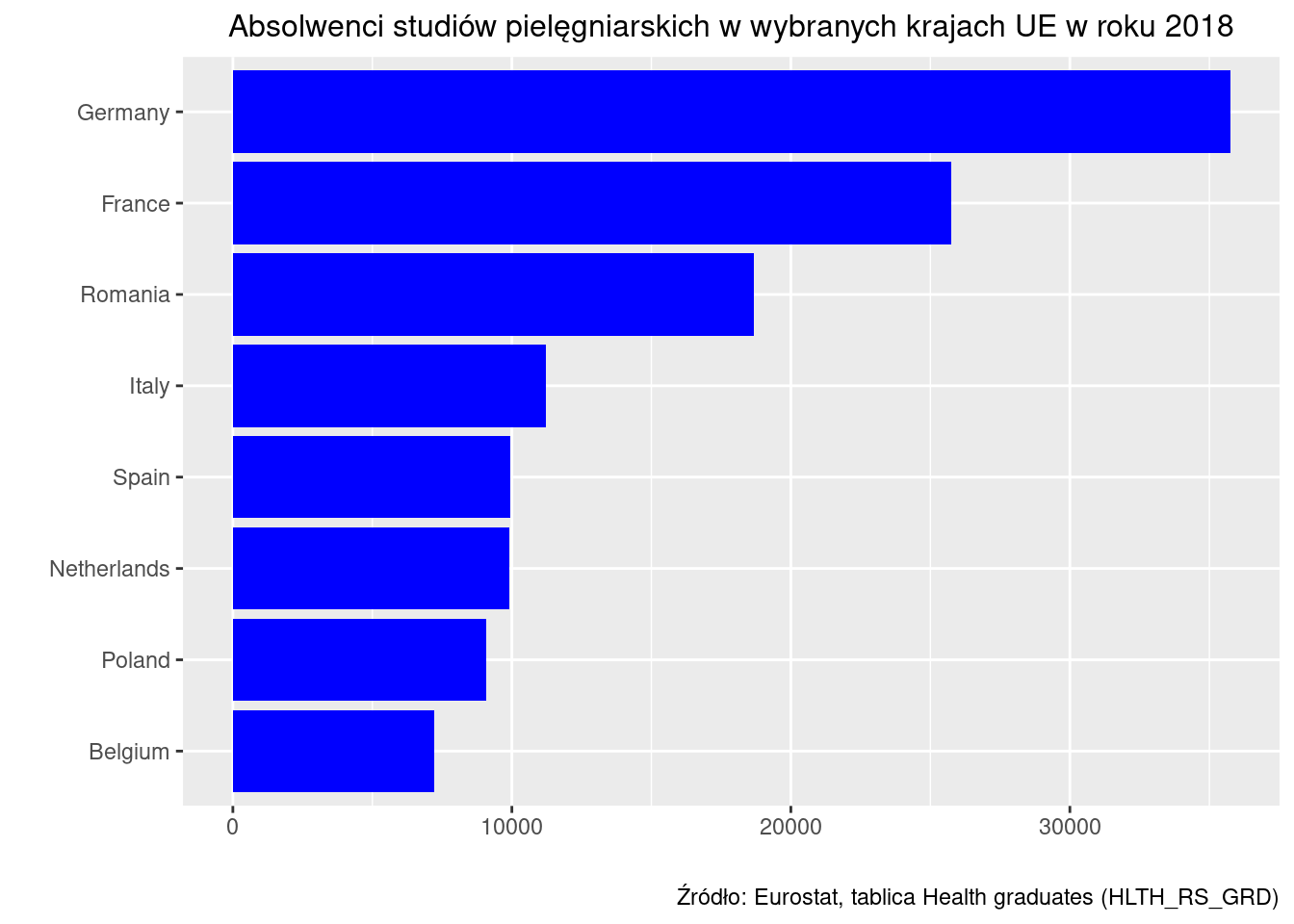
Wykres kołowy (pie chart)
Na wykresie kołowym długość łuku każdego wycinka (a także kąt środkowy oraz pole wycinka) jest proporcjonalna do liczebności, którą reprezentuje. Łącznie wszystkie wycinki tworzą pełne koło.
2.5 
Wykres słupkowy i kołowy przedstawiają dokładnie to samo, zatem który wybrać?
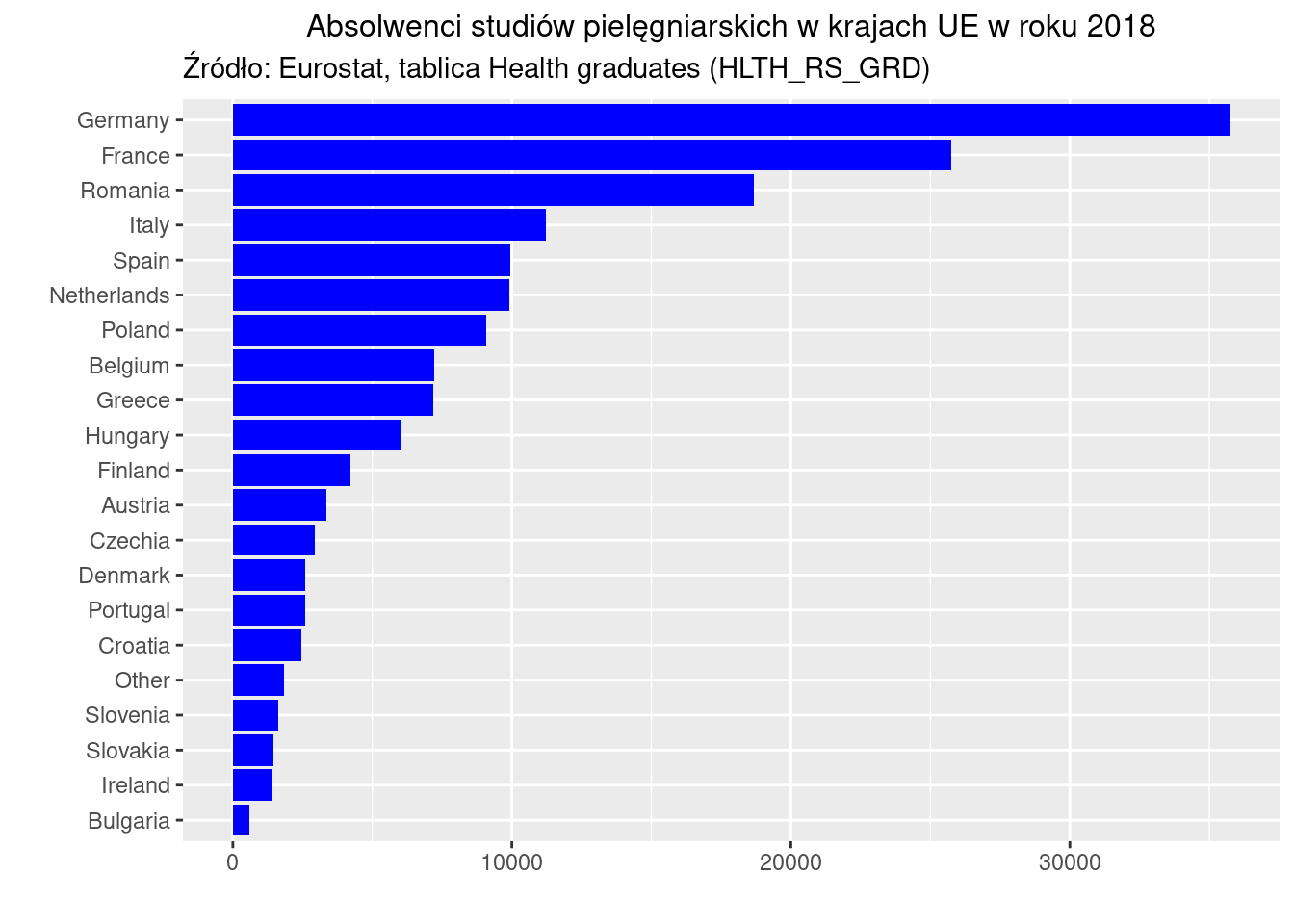
Wykres kołowy wygląda zapewne efektowniej (z uwagi na paletę kolorów), ale jest mniej efektywny. Wymaga dodania legendy, która utrudnia interpretację treści. Jeżeli zwiększymy liczbę krajów, to wykres kołowy staje się zupełnie nieczytelny, bo brakuje rozróżnialnych kolorów, a wycinki koła są zbyt wąskie, żeby cokolwiek wyróżniały:
2.6 
Wykres słupkowy dalej jest natomiast OK:
2.2.2 Skala liczbowa
Histogram to coś w rodzaju wykresu słupkowego, tyle że na osi OX zamiast wariantów zmiennej są przedziały wartości.
2.7 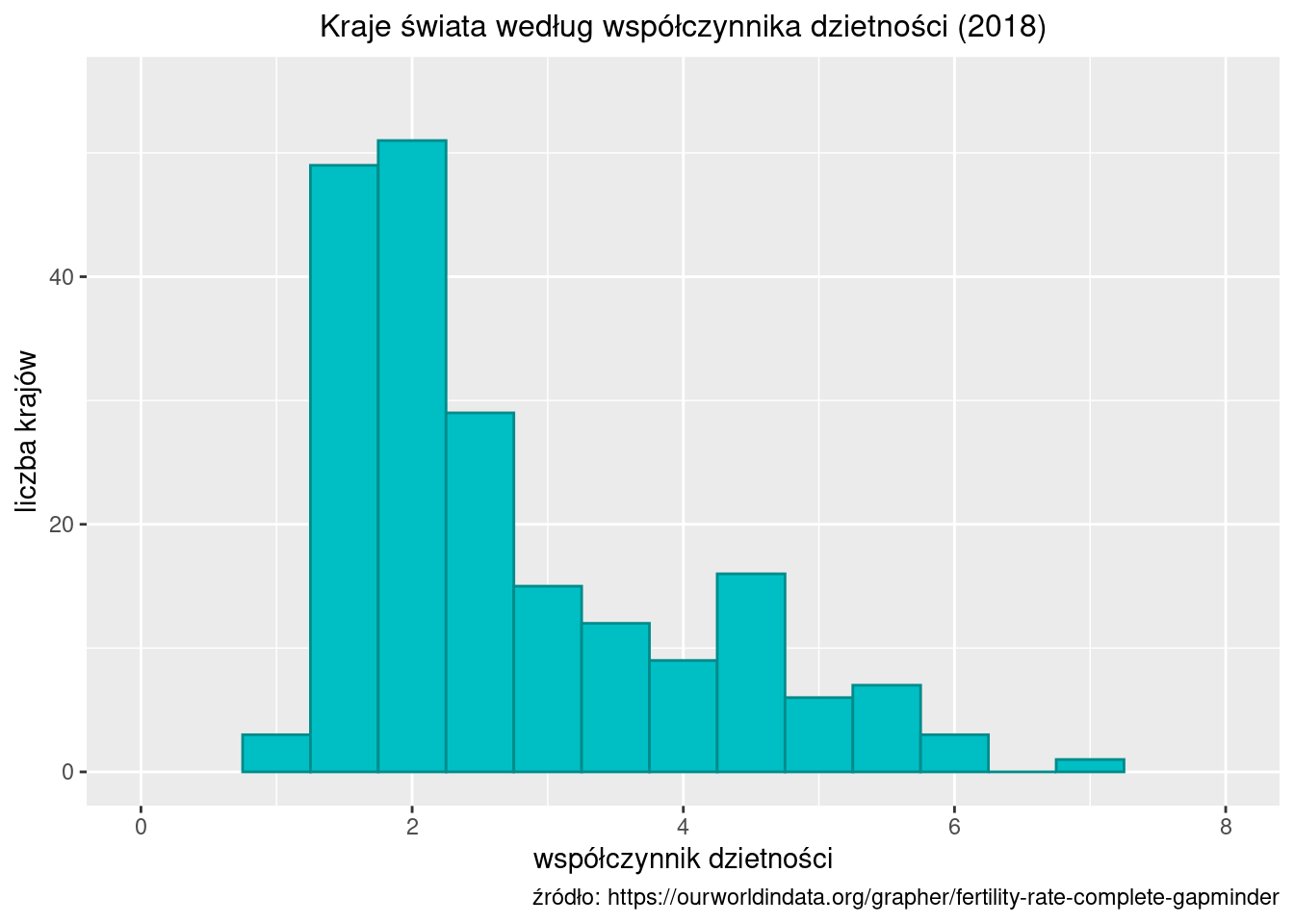
Im więcej przedziałów (mniejsza rozpiętość przedziału), tym histogram jest bardziej szczegółowy, co niekoniecznie jest pożądane, bo zaciemnia ogólny obraz. Nie ma złotych recept na to, ile powinno być przedziałów, a ich liczba determinuje kształt oraz optyczną wielkość histogramu. Im mniej przedziałów, tym histogram będzie optycznie większy. W powyższym przykładzie rozpiętość przedziału jest równa 0,5.
2.3 Statystyczka Florence Nightingale
Nie każdy, kto wie, kim była Florence Nightingale, wie, że była ona także statystykiem. W czasie wojny krymskiej nie tylko zorganizowała opiekę nad rannymi żołnierzami, ale również – aby przekonać swoich przełożonych do zwiększenia nakładów na szpitale polowe – prowadziła staranną ewidencję szpitalną oraz zgromadzone dane potrafiła analizować, używając wykresów własnego projektu.
W szczególności słynny jest diagram Nightingale zwany także różą Nightingale (rys. 2.1), które wprawdzie (podobno) nie okazał się szczególnie użyteczny, ale przecież nie każdy nowy pomysł jest od razu genialny.
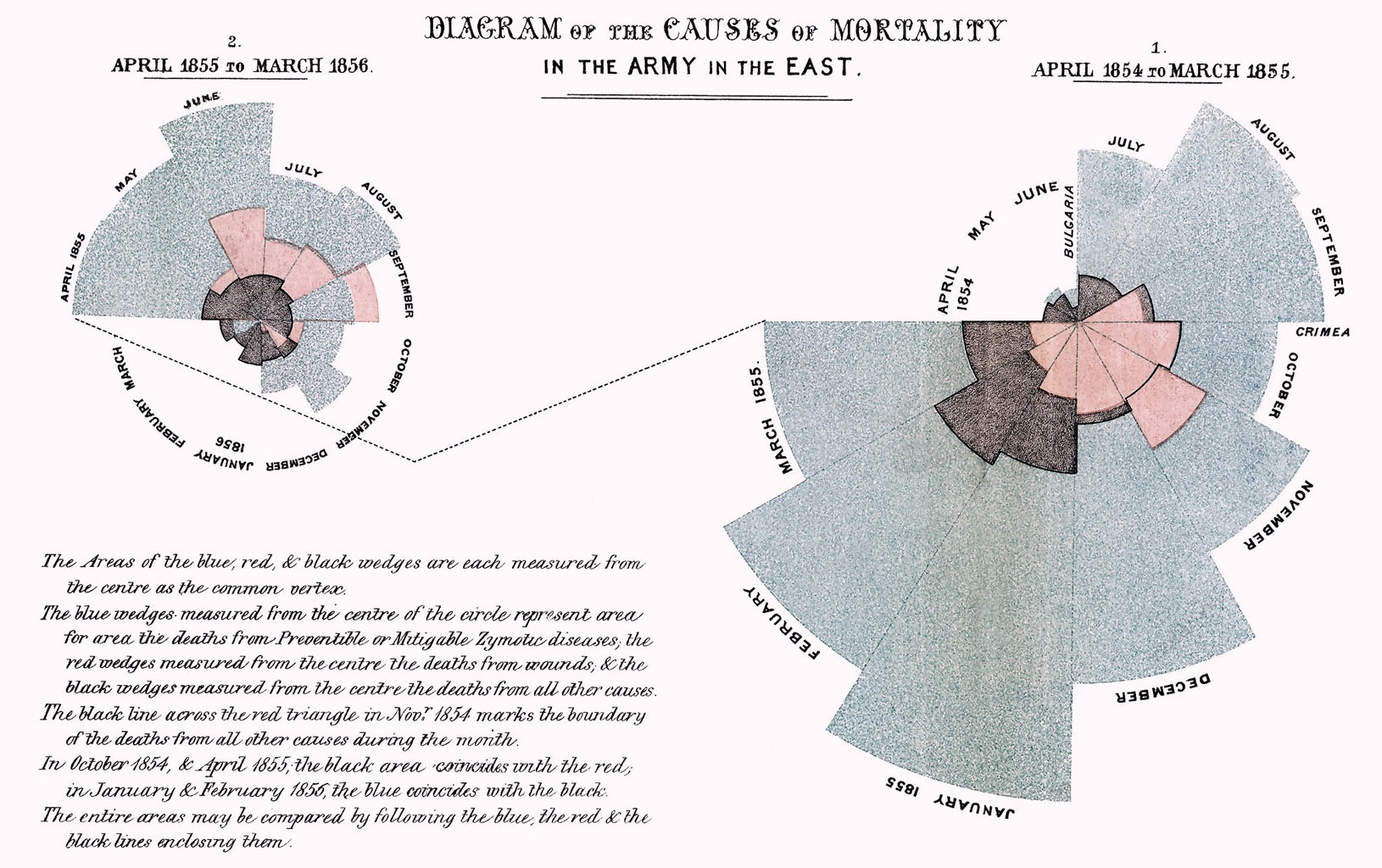
Rysunek 2.1: Róża Nightingale
Róża Nightingala to coś w rodzaju wykresu słupkowego, tyle że zamiast słupków są wycinki koła. Wycinków jest dwanaście, tyle, ile miesięcy. Długość promienia, a co za tym idzie wielkość pola wycinka, zależy od wielkości zjawiska, który reprezentuje (przyczyna śmierci: rany/choroby/inne).
Wpisując Florence+Nightingale, można znaleźć dużo informacji na temat, w tym: http://www.matematyka.wroc.pl/ciekawieomatematyce/pielegniarka-statystyczna.
W 1859 roku Nightingale została wybrana jako pierwsza kobieta na członka Royal Statistical Society (Królewskie Stowarzyszenie Statystyczne) oraz została honorowym członkiem American Statistical Association (Amerykańskiego Stowarzyszenia Statystycznego).
Szanowni czytelnicy – wnioski są oczywiste.
2.4 Analiza parametryczna
Analiza parametryczna z oczywistych względów dotyczy tylko zmiennych mierzonych na skali liczbowej.
2.4.1 Miary położenia
Miary przeciętne (położenia) charakteryzują średni lub typowy poziom wartości zmiennej. Są to więc takie wartości, wokół których skupiają się wszystkie pozostałe wartości analizowanej zmiennej.
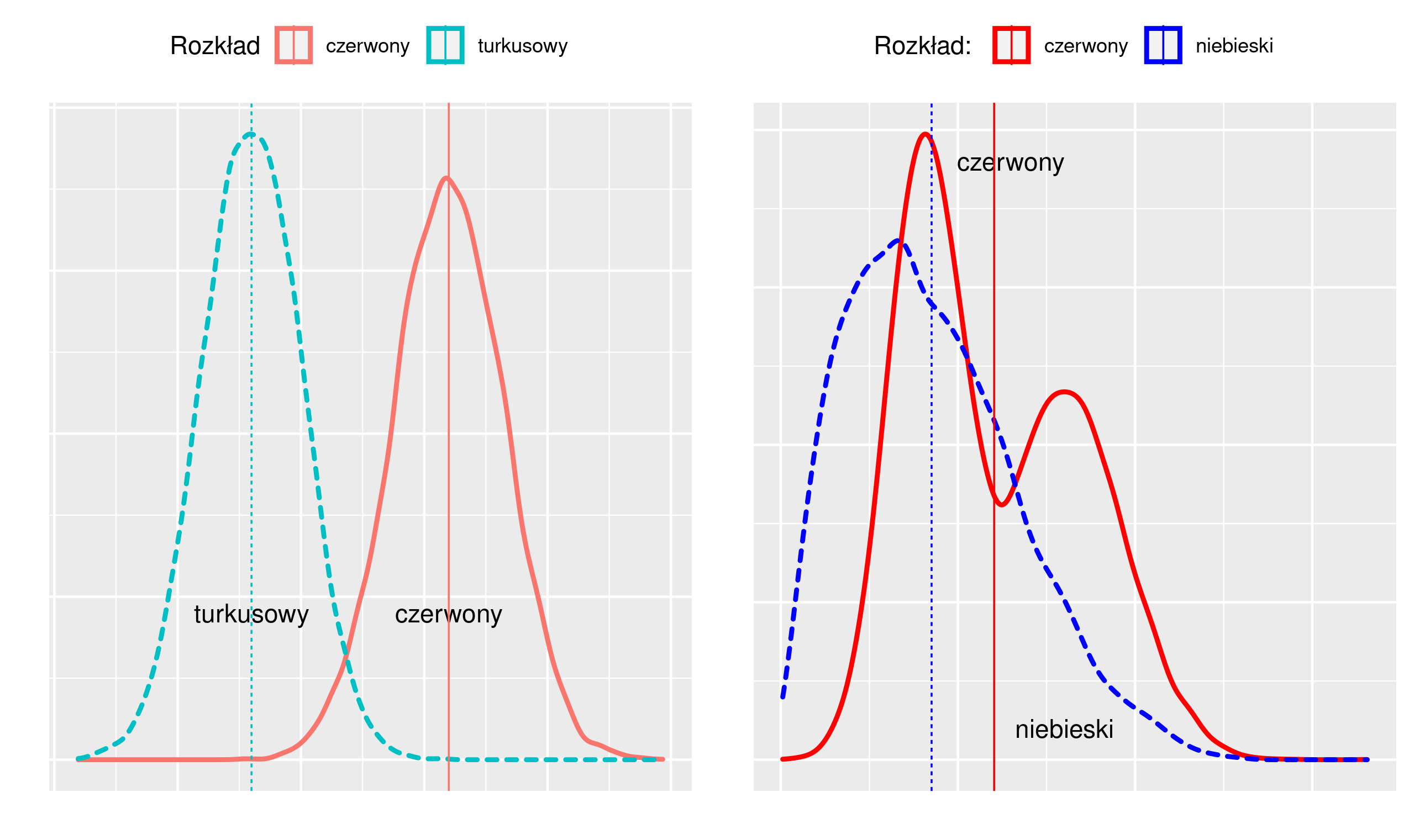
Rysunek 2.2: Rozkłady zmiennej a miary średnie
Na rysunku 2.2 po lewej mamy dwa rozkłady różniące się poziomem przeciętnym. Rozkład czerwony ma przeciętnie większe wartości niż turkusowy. Są to rozkłady jednomodalne, czyli takie, w których rozkład zmiennej skupia się wokół jednej wartości. Dla takich rozkładów ma sens obliczanie średniej arytmetycznej. Te średnie wartości są zaznaczone na rysunku linią pionową.
Na rysunku po prawej mamy rozkłady nietypowe: wielomodalne (czerwony) lub niesymetryczne (niebieski). W rozkładzie niesymetrycznym wartości skupiają się nie centralnie, ale po prawej/lewej od środka przedziału zmienności/wartości średniej).
W świecie rzeczywistym zdecydowana większość rozkładów jest jednomodalna. Rzadkie przypadki rozkładów wielomodalnych zwykle wynikają z łącznego analizowania dwóch różniących się wartością średnią zbiorów danych. Oczywistym zaleceniem w takiej sytuacji jest analiza każdego zbioru oddzielnie.
Rodzaje miar położenia:
- klasyczne:
- średnia arytmetyczna,
- pozycyjne:
- mediana,
- dominanta,
- kwartyle,
- ewentualnie kwantyle, decyle, centyle (rzadziej używane).
Średnia arytmetyczna (mean, arithmetic mean), to łączna suma wartości podzielona przez liczbę sumowanych jednostek. Jeżeli wartość \(i\)-tej jednostki w zbiorowości o liczebności \(N\) oznaczymy jako \(x_i\) (gdzie: \(i=1,\ldots, N\)), to średnią można zapisać jako:
\[\bar x = (x_1 + x_2 + \cdots + x_N)/N\]
Uwaga: we wzorach statystycznych zmienne zwykle oznacza się małymi literami, a średnią dla zmiennej przez umieszczenie nad nią kreski poziomej, czyli \(\bar x\) to średnia wartość zmiennej \(x\).
Mediana (median, kwartyl drugi) dzieli uporządkowaną zbiorowość na dwie równe części; połowa jednostek ma wartości zmiennej mniejsze lub równe medianie, a połowa wartości zmiennej równe lub większe od mediany. Stąd też mediana bywa nazywana wartością środkową. Mediana jest oznaczana symbolem Me.
Własności mediany: odporna na wartości nietypowe (w przeciwieństwie do średniej).
Dominanta (mode), wartość najczęściej występująca. Jeżeli rozkład jest wielomodalny, to dominanta jest nieokreślona. W szczególności w zbiorowościach o małej liczebności mogą być problemy z ustaleniem dominanty. Dominanta jest oznaczana symbolem D lub Mo.
Kwartyle (quartile): coś jak mediana, tylko bardziej szczegółowo. Są trzy kwartyle, które dzielą zbiorowość na cztery równe części, każda zawierająca 25% całości. Kwartyle oznaczane są symbolami \(Q_1\), \(Q_2\), \(Q_3\).
Pierwszy kwartyl dzieli uporządkowaną zbiorowość w proporcji 25%–75%. Trzeci dzieli uporządkowaną zbiorowość w proporcji 75%–25%. Drugi kwartyl to mediana.
Kwantyle (D, wartości dziesiętne), podobnie jak kwartyle, tyle że dzielą na 10 części.
Centyle (P, wartości setne), podobnie jak kwantyle, tyle że dzielą na 100 części. Przykładowo 99% jednostek w populacji ma wartość równą wartości 99 centyla i mniejszą.
2.8 Współczynnik dzietności na świecie w roku 2018
Średnia: 2,68. Interpretacja: średnia wartość współczynnika dzietności wyniosła 2,68 dziecka. Mediana: 2,2. Interpretacja mediany: wartość współczynnika dzietności w połowie krajów na świecie wynosiła 2,2 dziecka i mniej. Dominanta: 1,98. Interpretacja dominanty: najwięcej krajów wykazuje współczynnik dzietności równy 1,98. Wartość cokolwiek przypadkowa, bowiem krajów wykazujących współczynnik równy 1,98, jest raptem 4.
Uwaga: średnia dzietność na świecie nie wynosi 2,68 dziecka (bo po pierwsze uśredniamy kraje, a nie kobiety, a po drugie kraje różnią się liczbą ludności). Podobnie dzietność połowy kobiet na świecie wyniosła 2,2 dziecka i mniej jest niepoprawną interpretacją mediany (z tych samych względów jak w przypadku średniej).
Generalna uwaga: interpretacja średniej-średnich często jest nieoczywista i należy uważać (a współczynnik dzietności jest średnią: średnia liczba dzieci urodzonych przez kobietę w wieku rozrodczym. Jeżeli liczymy średnią dla 202 krajów, to mamy średnią-średnich). Inny przykład: odsetek ludności w wieku poprodukcyjnym według powiatów (średnia z czegoś takiego nie da nam odsetka ludności w wieku poprodukcyjnym w Polsce, bo powiaty różnią się liczbą ludności).
2.9 Współczynnik dzietności (kontynuacja):
Pierwszy kwartyl: 1,75; trzeci kwartyl 3,56, co oznacza, że 25% krajów miało wartość współczynnika dzietności nie większą niż 1,75 dziecka, a 75% krajów miało wartość współczynnika dzietności nie większą niż 3,56 dziecka.
2.4.2 Miary zmienności
Miary zmienności mierzą zmienność (rozproszenie) w zbiorowości.
Rodzaje miar zmienności:
- Klasyczne:
- wariancja i odchylenie standardowe,
- Pozycyjne:
- rozstęp,
- rozstęp ćwiartkowy.
Wariancja (variance) jest to średnia arytmetyczna kwadratów odchyleń poszczególnych wartości zmiennej od średniej arytmetycznej zbiorowości. Można to zapisać jako (\(\bar x\) oznacza średnią, \(N\) liczebność zbiorowości, a \(x_i\) wartość \(i\)-tej jednostki):
\[s^2 = \frac{1}{N} \left( (x_1 - \bar x)^2 + (x_2 - \bar x)^2 + \cdots + (x_N - \bar x)^2 \right)\]
Przy czym często zamiast dzielenia przez \(N\) dzielimy przez \(N-1\).
Odchylenie standardowe (standard deviation) jest pierwiastkiem kwadratowym z wariancji. Parametr ten określa przeciętną różnicę wartości zmiennej od średniej arytmetycznej. Odchylenie standardowe jest oznaczane symbolem \(s\).
Rozstęp jest to różnica pomiędzy największą a najmniejszą wartością zmiennej w zbiorowości: \(R = x_{\max} - x_{\min}\). Rzadko stosowana miara, bo jej wartość zależy za bardzo od wartości nietypowych.
Rozstęp ćwiartkowy (interquartile range, IQR) ma banalnie prostą definicję: \(R_Q = Q_3 - Q_1\), gdzie: \(Q_1\), \(Q_3\) oznaczają odpowiednio pierwszy oraz trzeci kwartyl.
2.10 Współczynnik dzietności (kontynuacja)
Średnie odchylenie od średniej wartości współczynnika wynosi 1,25 dziecka. Wartość rozstępu ćwiartkowego wynosi 1,81 dziecka. Wartość rozstępu wynosi 5,18 dziecka.
Uwaga: odchylenie standardowe/ćwiartkowe są miarami mianowanymi. Zawsze należy podać jednostkę miary.
2.4.3 Miary asymetrii
Asymetria albo skośność (skewness) jest odwrotnością symetrii. Rozkład jest symetryczny jeżeli jednostki są rozłożone „równomiernie” wokół wartości średniej. W rozkładzie symetrycznym wartości średniej i mediany są sobie równe. Skośność może być dodatnia (positive skew) lub ujemna (negative skew). W przypadku asymetrii prawostronnej większa część zbiorowości przyjmuje wartości poniżej średniej. W przypadku asymetrii lewostronnej jest odwrotnie. Rysunek 2.3 przedstawia rozkład symetryczny oraz rozkłady skośne.
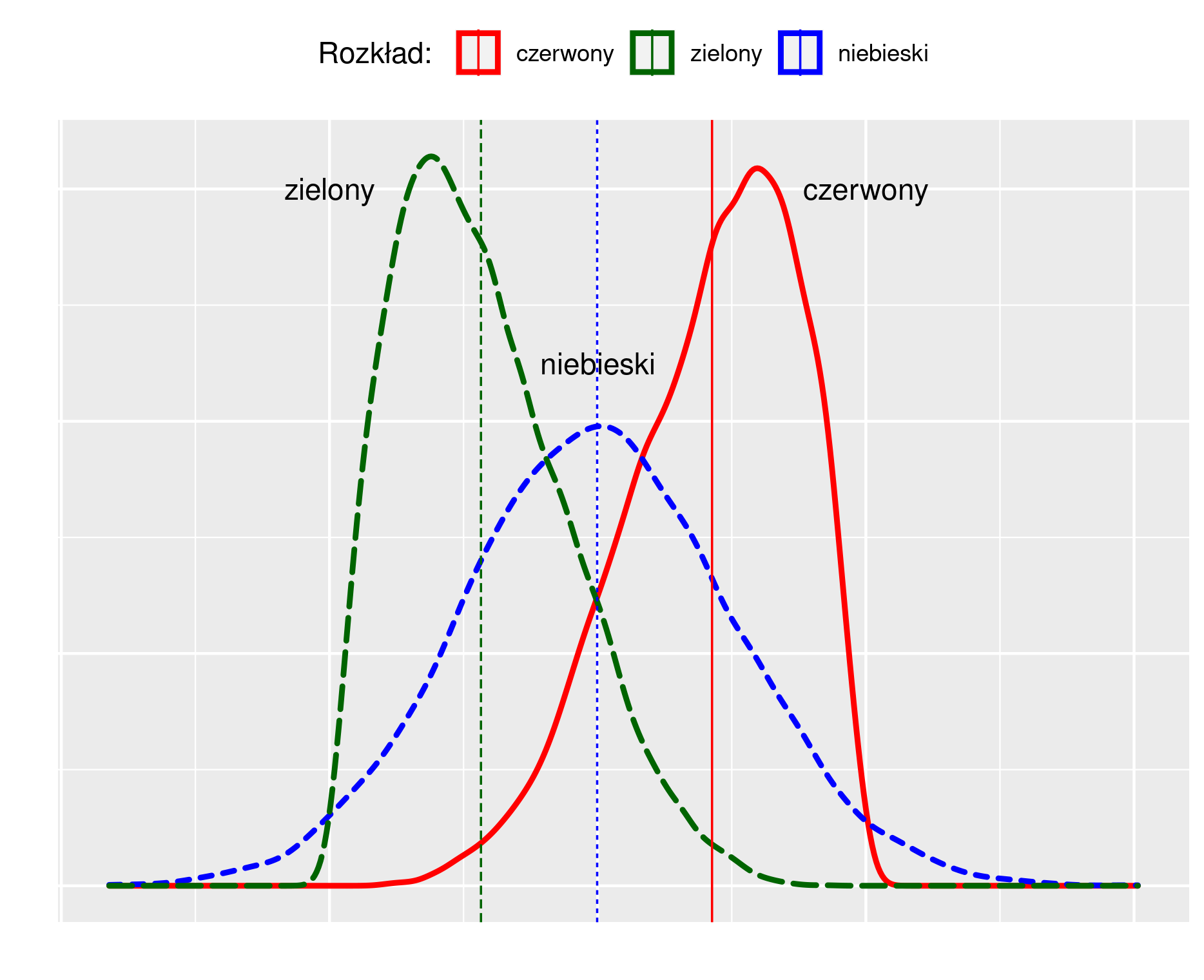
Rysunek 2.3: Rozkłady symetryczne i asymetryczne
Miary asymetrii:
klasyczny współczynnik asymetrii (\(g\)):
Przyjmuje wartości ujemne dla asymetrii lewostronnej; a dodatnie dla prawostronnej. Teoretycznie może przyjąć dowolnie dużą wartość, ale w praktyce rzadko przekracza 3 co do wartości bezwzględnej.
Wartości większe od 2 świadczą o dużej, a większe od 3 o bardzo dużej asymetrii.
współczynniki asymetrii Pearsona (\(W_s\)):
Wykorzystuje różnice między średnią a dominantą: \(W_s = (\bar x - D)/s\).
Wykorzystuje różnice między średnią a medianą: \(W_s = 3(\bar x - Me)/s\).
Współczynnik asymetrii oparty na odległościach między kwartylami:
- Obliczany jest według następującej formuły: \(W_{sq} = ((Q_3 - Q_2) - (Q_2 - Q_1))/ (Q_3 - Q_1)\).
2.11 Współczynnik dzietności (kontynuacja)
Współczynnik asymetrii \(g\) wynosi 1,06. Współczynnik Pearsona wykorzystujący dominantę wynosi 0,56, a wykorzystujący medianę – 1,14. Wartość współczynnika opartego na kwartylach wynosi 0,5. Wszystkie współczynniki wskazują prawostronną (dodatnią) asymetrię. Współczynniki oparte na dominancie i kwartylach wskazują słabą asymetrię, a oparte na medianie oraz klasyczny umiarkowaną. Jest całkowicie normalne, że różne miary wykazują różne natężenie asymetrii.
2.5 Porównanie wielu rozkładów
Często strukturę jednego rozkładu należy porównać z innym. Albo trzeba porównać strukturę wielu rozkładów. Pokażemy na przykładzie, jak to zrobić.
2.12 Masa ciała uczestników Pucharu Świata w rugby
W grze w rugby drużyna jest podzielona na dwie formacje: ataku i młyna. Należy porównać rozkład masy ciała zawodników obu formacji uczestniczących w turniejach o Puchar Świata w rugby w 2015, 2019 i 2023 roku.
Zawodnicy ataku
Histogram przy przyjęciu długości przedziału równej 4 kg (pionowa linia zielona oznacza poziom średniej):
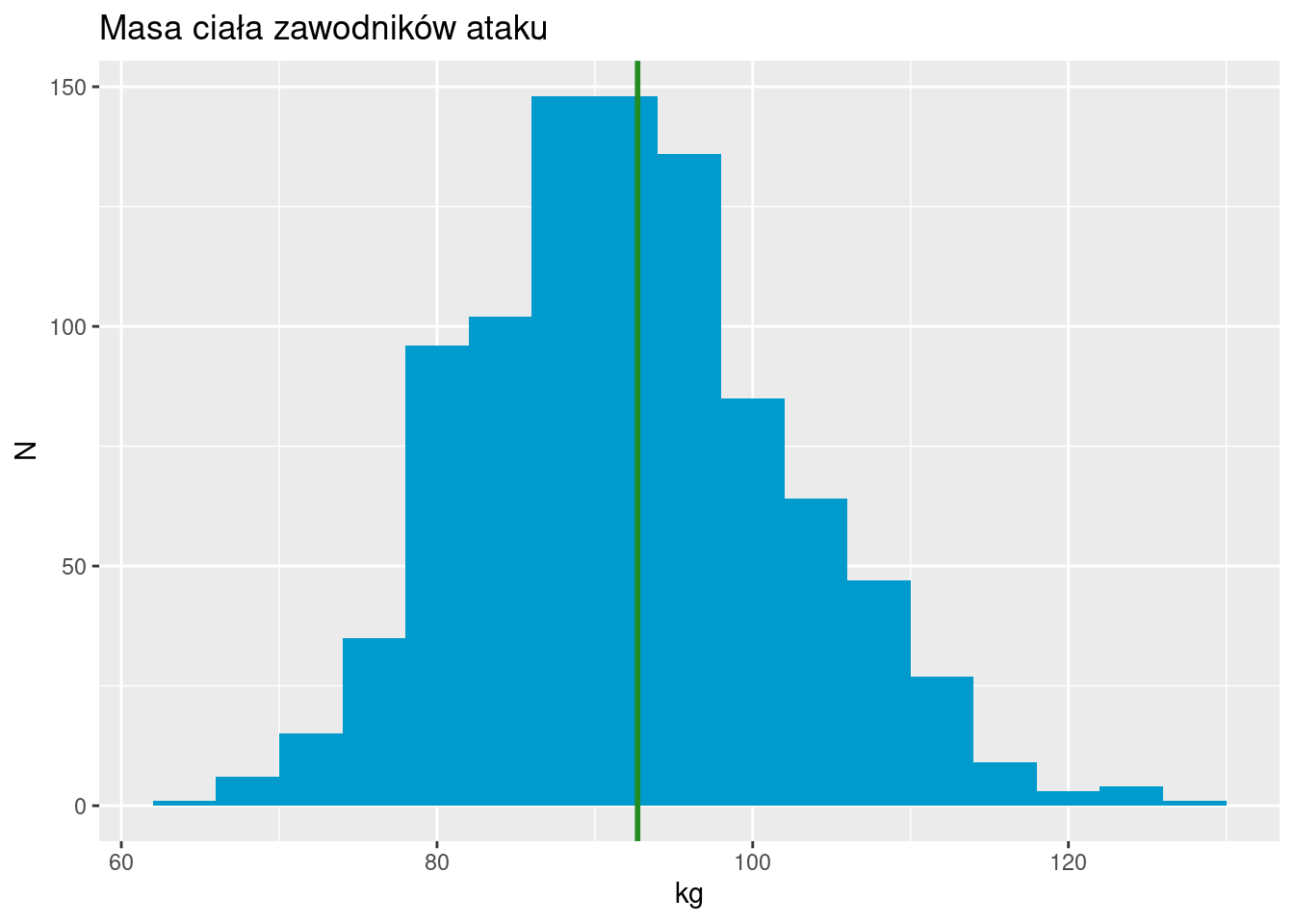
Liczba zawodników ataku wyniosła 936. Przeciętnie zawodnik ataku ważył 92,7 kg. Wartość mediany wyniosła 92 kg (połowa zawodników ataku ważyła 92 kg i mniej). Wartości pierwszego i trzeciego kwartyla wyniosły odpowiednio 85,5 oraz 99 kg (1/4 zawodników ataku ważyła 85,5 kg i mniej; 1/4 zawodników ataku ważyła 99 kg i więcej).
Odchylenie standardowe jest równe 10,1 kg (przeciętnie odchylenie od średniej arytmetycznej wynosi 10,1 kg). Rozstęp ćwiartkowy wynosi 13,5 kg (rozstęp 50% środkowych wartości wynosi 13,5 kg).
Wartość klasycznego współczynnika skośności jest równa 0,34. Wartość współczynnika skośności opartego na kwartylach wynosi 0,04, a współczynnika skośności Pearsona wykorzystującego medianę wynosi 0,21.
Zawodnicy młyna
Histogram przy przyjęciu długości przedziału równej 4 kg (pionowa linia zielona oznacza poziom średniej):

Liczba zawodników młyna wyniosła 943. Średnio zawodnik młyna ważył 112,3 kg. Wartość mediany wyniosła 112 kg (połowa zawodników młyna ważyło 112 kg i mniej). Wartości pierwszego i trzeciego kwartyla wyniosły odpowiednio 106 oraz 118 kg (1/4 zawodników młyna ważyło 106 kg i mniej; 1/4 zawodników młyna ważyło 118 kg i więcej).
Odchylenie standardowe jest równe 9,2 kg (przeciętnie odchylenie od średniej arytmetycznej wynosi 9,2 kg). Rozstęp ćwiartkowy wynosi 12 kg (rozstęp 50% środkowych wartości wynosi 12 kg).
Wartość klasycznego współczynnika skośności jest równa 0,17. Wartość współczynnika skośności opartego na kwartylach wynosi 0, a współczynnika skośności Pearsona wykorzystującego medianę wynosi 0,11.
Porównanie atak vs młyn
| miara | atak | młyn |
|---|---|---|
| średnia | 92,71 | 112,33 |
| mediana | 92,00 | 112,00 |
| odchyl.standard. | 10,07 | 9,24 |
| odchyl.ćwiartkowe | 13,50 | 12,00 |
| skośność | 0,34 | 0,17 |
Średnio zawodnik młyna ważył prawie 20 kg więcej od zawodnika ataku (w przypadku mediany jest to dokładnie 20 kg więcej). Zmienność mierzona wielkością odchylenia standardowego oraz \(Q_R\) jest w obu grupach podobna. Oba rozkłady są zbliżone do rozkładu symetrycznego.

2.5.1 Wykres pudełkowy
Do porównania wielu rozkładów szczególnie użyteczny jest wykres zwany pudełkowym (box-plot).
Pudełka na wykresie pudełkowym są rysowane według następujących zasad (por rysunek 2.4):
- lewy i prawy bok pudełka jest równy kwartylom;
- linia pionowa w środku pudełka jest równa medianie;
- linie poziome (zwane wąsami) mają długość równą \(Q_1 - 1,5 \cdot Q_R\) oraz \(Q_3 + 1,5 \cdot Q_R\) (dla przypomnienia: \(Q_1\), \(Q_3\) to kwartyle, zaś \(Q_R\) to rozstęp ćwiartkowy);
- kropki przed oraz za wąsami to wartości zmiennej większe od \(Q_3 + 1,5 \cdot Q_R\) lub mniejsze od \(Q_1 - 1,5\cdot Q_R\).
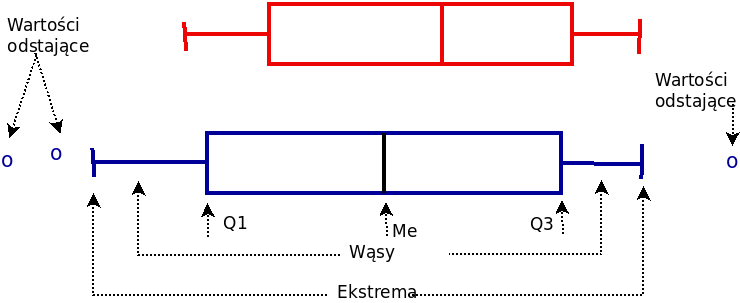
Rysunek 2.4: Wykres pudełkowy
Interpretacja pudełek:
- linia pozioma w środku pudełka określa przeciętny poziom zjawiska;
- długość pudełka oraz wąsów określa zmienność (im większe wąsy/długość pudełka tym większa zmienność);
- kropki przed oraz za wąsami to obserwacje nietypowe (albo wartości odstające).
Zatem dolny rozkład z rysunku 2.4 ma mniejszą wartość średnią oraz większą zmienność od rozkładu górnego. Dolny rozkład posiada też wartości odstające, a górny nie.
Zwróćmy uwagę na następującą sztuczkę. Wartości nietypowe nie są definiowane jako np. górne/dolne 1% wszystkich wartości, bo wtedy każdy rozkład miałby wartości nietypowe, ale jako wartości mniejsze lub większe od \(Q_{1,3} \pm 1,5 \cdot Q_R\). Wszystkie wartości rozkładów o umiarkowanej zmienności mieszczą się wewnątrz tak zdefiniowanego przedziału.
Typowo wykres zawiera wiele pudełek, a każde pudełko wizualizuje jeden rozkład. Pudełka mogą być umieszczone jedno pod drugim, tak jak na rysunku 2.4 lub jedno obok drugiego jak na przykładach poniżej.
2.13 Masa ciała rugbystów
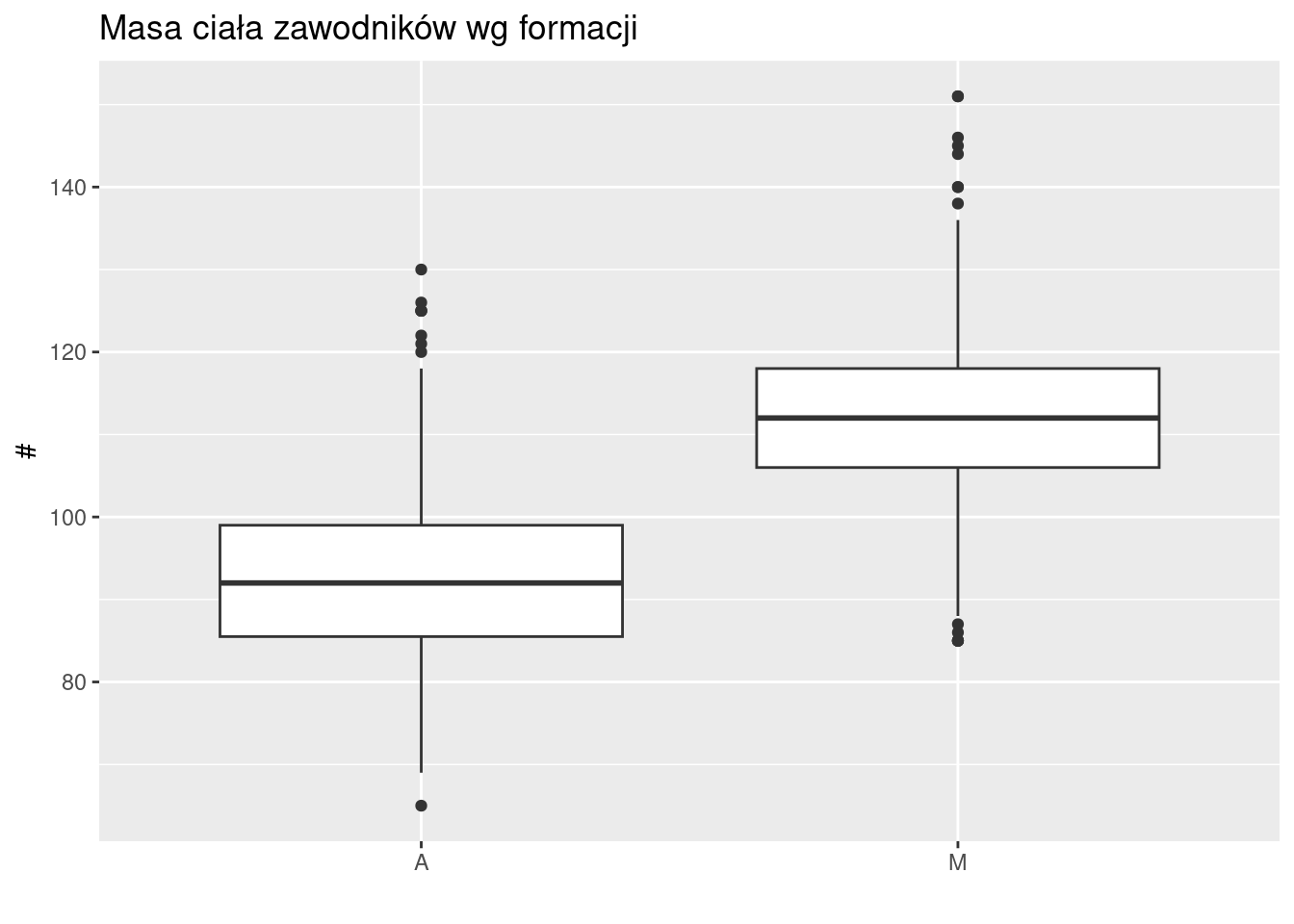
Z wykresu od razu widać, który rozkład ma wyższą średnią (M), który większe rozproszenie (A) oraz w którym występują wartości nietypowe.
Pudełek może być oczywiście więcej niż dwa. Następny przykład pokazuje porównanie rozkładów masy ciała zawodników rugby na poszczególnych turniejach.
2.14 Masa ciała rugbystów
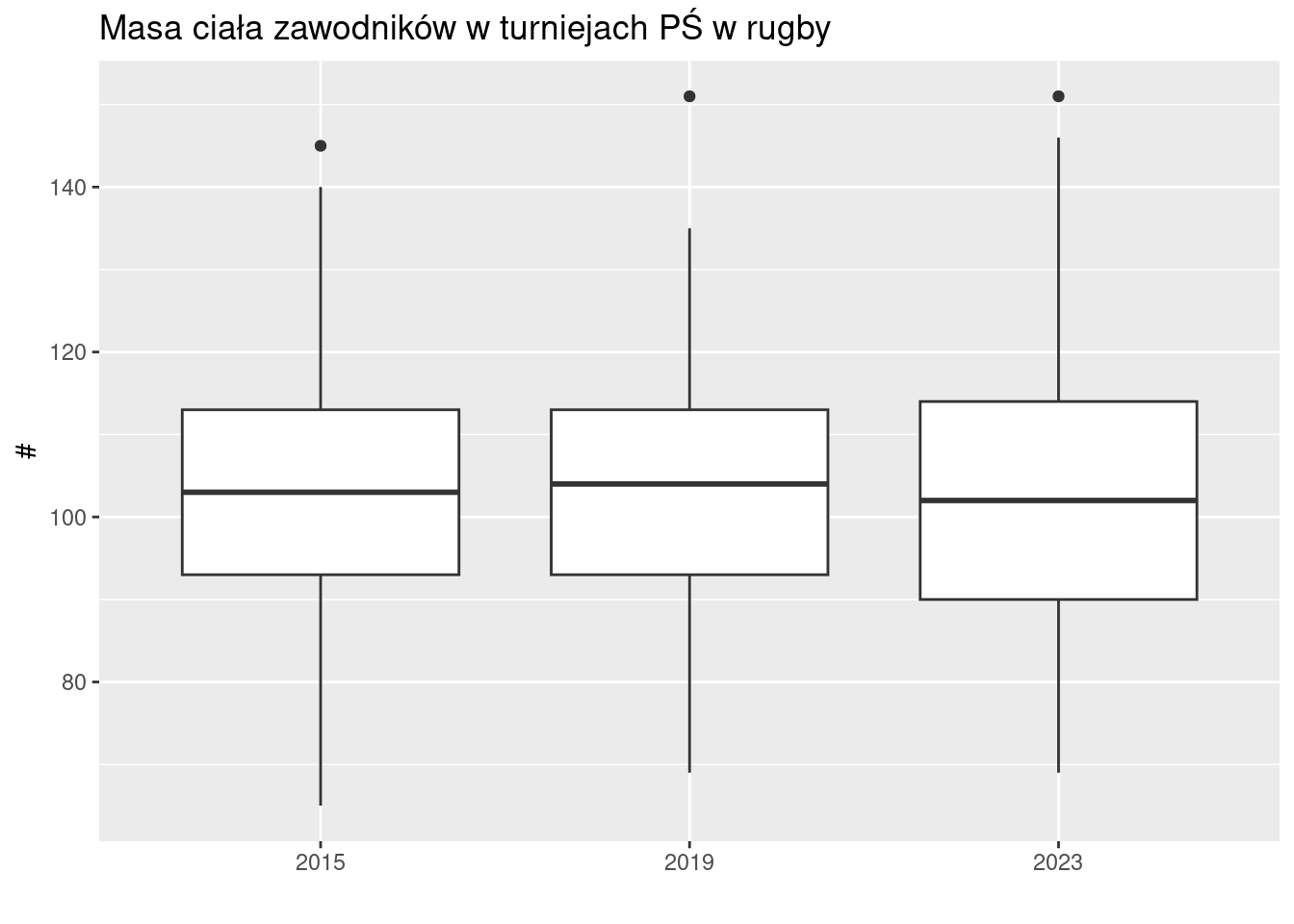
Od razu widać, że przeciętnie najciężsi zawodnicy byli na turnieju w roku 2019; największe zróżnicowanie masy ciała występowało na turnieju w roku 2023.
2.6 Zestawienie metod opisu statystycznego
W rozdziale przedstawiono osiem sposobów opisania rozkładu zmiennej:
Tablice statystyczne.
Wykres słupkowy.
Wykres kołowy (niezalecany).
Histogram.
Wykres pudełkowy.
Miary tendencji centralnej: średnia, mediana, kwartyle.
Miary rozproszenia: odchylenie standardowe, rozstęp ćwiartkowy.
Miary asymetrii.